Summarize Content With:
What You Will Learn:
How to take your call recordings beyond storage and compliance by mining ai call data insights, from customer sentiment, objection detection, and trend identification, with the help of conversational AI technology that translates audio to text and generates insights to use in your CX, sales, and product processes. You will also learn about the different technology layers like acoustic modeling, speaker diarization, PII redaction, and LLMs that transform audio into insights.
AI call data insights are structured insights generated from recorded calls using AI and NLP. They target CX managers, sales teams, and product managers. They are important since the data in your call recordings already has the customer feedback analysis, objections, and sentiments that you have been paying surveys to estimate.
What Are AI-Powered Call Analytics?
AI-powered call analytics is the conversion of voice into text and then applying machine learning techniques to understand intent, sentiment, and outcomes in an automated manner. It replaces manual listening with continuous and passive information capture.
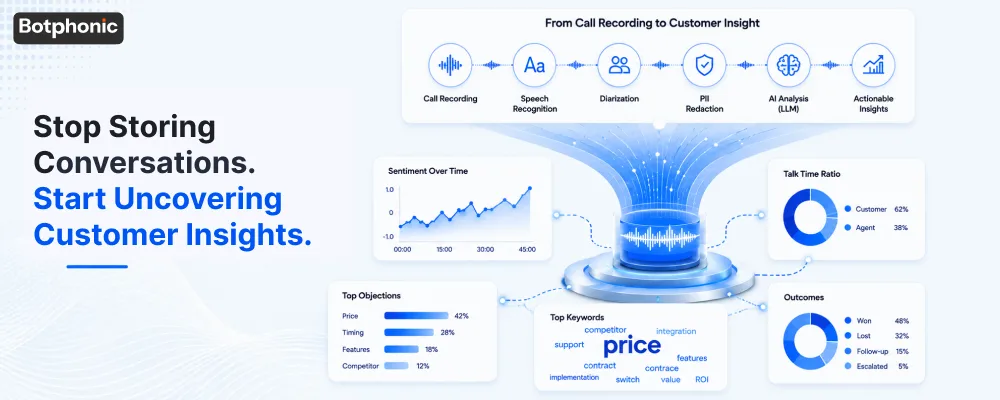
The Tech Layers Behind the Insights
It takes four different tech layers for any insight to show up on your dashboard.
Acoustic Modeling translates audio waveforms into phoneme probabilities. This layer accounts for noise, accent variability, and channel deterioration. The entire pipeline fails to perform without an effective acoustic modeling layer.
Phonetic Indexing allows keyword searches in the audio file, without the need for full transcription. Essentially, this layer translates spoken words into phoneme sequences, allowing the search for “churn” or “competitor” in thousands of hours of recordings without the need to fully transcribe.
Speaker Diarization identifies who spoke when. It assigns speakers to individual segments of the audio file, whether that speaker was the agent or the customer, making sure that subsequent analysis will know where the frustration peak originated from.
PII Redaction eliminates sensitive information such as credit card numbers, social security numbers, and other personal identifiers, both from the audio files and their transcriptions, before passing them to the analytics layer. This is an absolute compliance requirement, not an option.
These same technologies also power secure AI phone call systems, ensuring that recordings are processed with privacy, compliance, and intelligence built into every stage of the conversation lifecycle.
The above four layers allow LLMs to analyze the clean, attributed transcript and interpret its meaning.
“We used to spot-check 5% of calls and guess at the rest. The moment we added diarization and LLM-based tagging, we discovered our top objection wasn’t price — it was trust. That single insight rewrote our entire onboarding sequence.”
— Head of Sales, mid-market SaaS company (150 seats, B2B)
The Anatomy of a Call: Manual Review vs. AI Pipeline
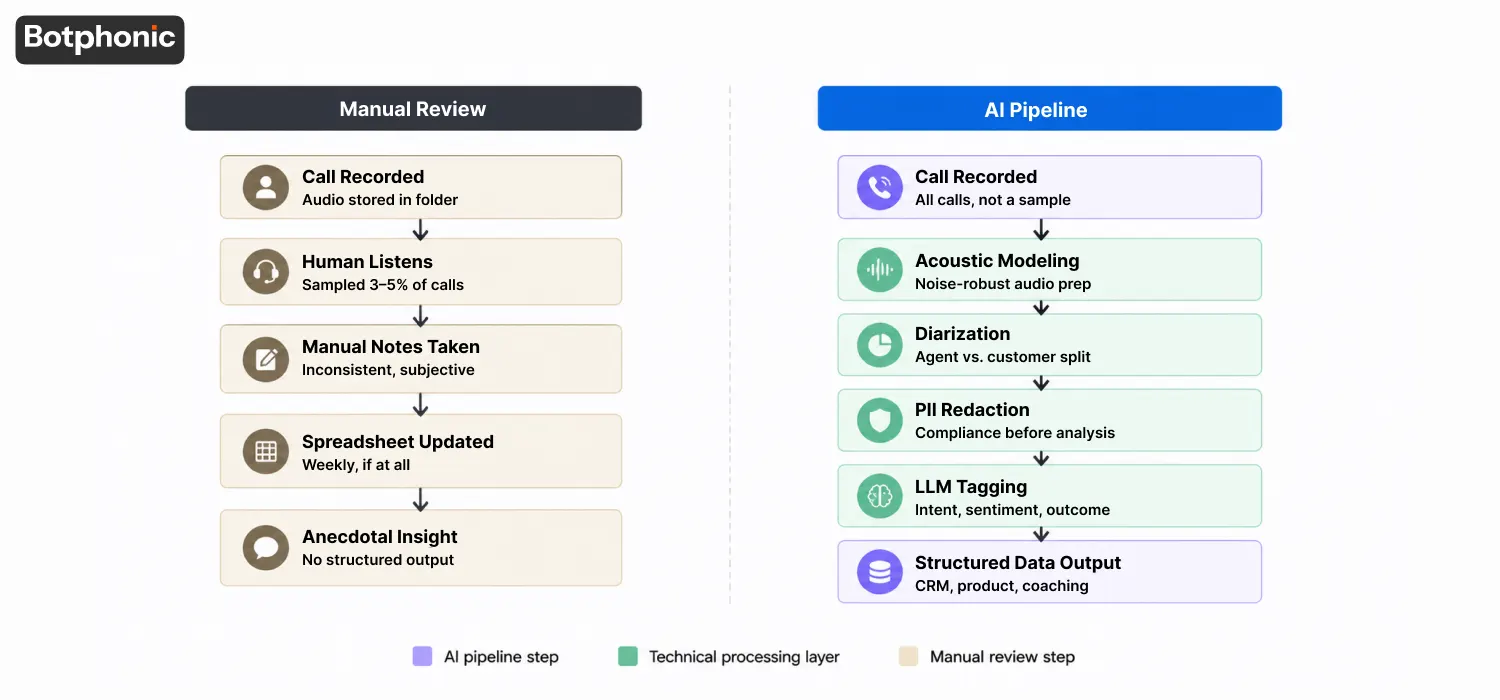
The diagram makes the gap concrete. Manual review is five steps ending in anecdotal notes. The AI pipeline adds three technical layers, acoustic modeling, diarization, and PII redaction, before any LLM analysis begins. That foundation is what makes the insight trustworthy.
Why Are Companies Continuing To View Call Recordings As Dead Data?
Companies record calls for regulatory purposes, but don’t do anything with the recordings after. They sit in a file folder, accruing storage costs, but providing no insights whatsoever.
Businesses using an AI call assistant can automatically capture, organize, and analyze conversations, transforming every customer interaction into actionable intelligence instead of leaving recordings unused.
The reason for that was that in order to analyze call recording, a data science team was needed. Not anymore. Conversational AI solutions have democratized analysis of recordings to anyone who has call volume and use cases.
The Scale Issue that No Survey Can Help You With
Analysis of customer feedback from surveys provides only 5-10% of all your interaction insights. There’s response bias – post-call star ratings can tell you about the satisfaction level, but not the reasons behind that.
According to Salesforce’s State of the Connected Customer report, 66% of customers expect a company to understand their needs and expectations. Manual review of call recordings will be too slow for that expectation at scale.
AI can listen to every single call. Surveys cannot.
Real-Life Experience of High Volume Teams
In practice, high-volume sales teams working with tools such as call intelligence by Botphonic consistently discover one thing – their most popular objection was out of anyone’s radar.
Pattern: Customers express pricing concerns in the first 90 seconds of a call. Human quality reviewers, conducting spot-checking 3% of calls, were unaware of this problem. AI detected it in the first week of implementation. The sales team revised their opening script. Conversion rates improved on this call type in 30 days.
“The diarization layer was the unlock for us. Once we could separate agent talk time from customer talk time, we found our reps were talking 68% of the time on lost deals versus 41% on won deals. That became our #1 coaching metric overnight.”
— CX Lead, e-commerce brand (2M+ annual calls)
How Do You Gain Voice-of-Customer Insights from Your Call Transcripts?
Gaining voice-of-customer insights through call analysis means utilizing artificial intelligence to detect patterns, recurring themes, language usage and customer phrasing without having to ask your customers twice.
It means conducting passive research at a scale that survey programs cannot achieve.
Automated Tagging of Customer Objections
Every sales conversation includes objections. And most of them go unnoticed, untagged, unlogged and unaddressed.
Customer insights AI detects objections from each call and identifies them by frequency, time and context. You learn that “too expensive” occurs 43% more often on Thursdays afternoon or prospects who mention “I need to think about it” are closing at half the rate.
The tools that include Gong, Chorus.ai, and the very analytics layer developed by Botphonic itself are explicitly designed to uncover such patterns automatically without manually tagged data.
Identifying Emerging Trends Faster Than Your Competition
Customers are constantly communicating their needs in every customer service call. But do you listen to them?
Trend identification within customer service voice data includes recognizing emerging clusters of keywords – product names, competitors’ names, requested features – long before they emerge in the quarterly NPS survey. This creates significant competitive advantage.
Phonetic indexing allows you to do that even before full transcription takes place. You can perform a search for a competitor’s name across millions of minutes of audio instantly.
 PRO TIP
PRO TIP
How Does Customer Sentiment Analysis Actually Work?
Customer sentiment analysis is the automated measurement of emotional tone — frustration, satisfaction, urgency, confusion — within spoken or transcribed conversation. Modern NLP models score sentiment at the sentence level, the call level, and across call segments.
Customer Sentiment Analytics vs. Traditional Metrics
A post-call star rating gives you one number per interaction. It doesn’t tell you which moment caused the drop. Customer sentiment analytics gives you the timeline.
| Metric Type | What It Captures | Granularity | Actionable? | Tech Layer |
| Post-call star rating | Overall satisfaction | Call-level | Limited | None |
| NPS survey | Loyalty likelihood | Relationship-level | Limited | None |
| Keyword frequency | Recurring themes and objections | Theme-level | High | Phonetic indexing |
| Customer sentiment analytics | Tone, urgency, frustration by segment | Sentence-level | High | LLM + NLP |
| Speaker-attributed sentiment | Agent vs. customer emotion separately | Speaker-level | Very high | Diarization + LLM |
The star rating indicates there was some problem. Sentiment analysis indicates when, where, and why the problem occurred. Speaker-specific sentiment — enabled by diarization — tells you which side caused the result.
Using Consumer Analytics for Customer Service Voice and Tone
With sentiment data, you can analyze its correlations with results. Calls where agents’ tones matched customers’ sense of urgency led to more closures. Calls where the use of passive language by agents during objection resulted in high churn correlation.
Consumer analytics in this way changes coaching. Coaching becomes about showing the call recording segment where sentiment dropped and what language precedes it, rather than simply advising an agent to be more empathetic.
Note: The accuracy of the sentiment analysis model depends on the transcription underneath it. Speech-to-text engine accuracy at 78% will translate into sentiment scores being off by the same amount. Models such as Google Speech AI or AWS Transcribe should be prioritized — they consistently score above 95% on clear audio. Below 90% accuracy makes customer sentiment analytics inaccurate for coaching and product decisions.
What Do You Need in AI Call Analytics Tools?
The right tool depends on your technical capacity, call volume, and how deeply you need to integrate insights into existing workflows. There are two primary paths: building on raw APIs yourself, or deploying a purpose-built SaaS platform.
DIY Python/API vs. SaaS Platform: Which Approach Fits Your Team?
This is the decision that most CX and sales leaders face when moving from storage to intelligence.
| Criteria | DIY (Python + APIs) | SaaS Platform (e.g., Botphonic) |
| Setup time | 4–12 weeks (depends on team) | 1–5 days |
| Transcription engine | Google Speech AI, AWS Transcribe, AssemblyAI via API | Built-in, often multi-engine |
| Diarization | Manual setup via pyannote.audio or AssemblyAI | Included out-of-the-box |
| PII redaction | Custom regex or NLP pipeline | Automated, compliance-ready |
| LLM tagging | GPT-4o / Claude via API, prompt engineering required | Pre-built tag libraries, configurable |
| CRM integration | Custom webhook or Zapier | Native connectors (HubSpot, Salesforce, etc.) |
| Ongoing maintenance | Your team owns model updates | Vendor-managed |
| Cost structure | Pay per API call + engineering hours | Per-seat or per-minute SaaS |
| Best for | Teams with ML engineers and specific custom needs | CX/sales leaders needing fast time-to-insight |
It will work well if you require very customized logic for the extraction process, if you have the existing data infrastructure set up or if you’re working on such a large scale that SaaS-based per-minute pricing becomes an issue. Python proficiency, audio processing expertise using libraries such as librosa or pyannote, and API call expertise with providers such as Google, AWS or AssemblyAI.
If we take the SaaS route (Botphonic is a perfect example), the strategy behind the product assumes the needs of the company in the current quarter, not next year. Acoustic modeling, diarization, PII redaction, LLM tagging, and CRM routing are all there. All that is left is to define the tags and let the platform do the magic.
PRO TIP
What Does the Strategic Implementation of AI Call Analytics Look Like?
Strategic implementation means building a repeatable workflow — not a one-time analysis project. It means centralizing data, defining extraction frameworks, and automating the feedback loop.
Step 1: Centralize Your Call Data
Recordings stored on desk phones, soft phones, or mobile applications can’t be analyzed equally well. Centralize first.
Botphonic, RingCentral, Dialpad are some of the platforms able to centralize call recordings in a single place. You don’t need five data sources – only one.
Step 2: Create Your Framework for Extraction
Decide which tags to apply prior to any work of the AI. Objection tags could be pricing, timing, competitor, or trust; outcome tags – booked, lost, follow-up needed, or escalated; sentiment tags – frustrated, satisfied, confused, urgent.
Customer insight AI solutions such as Botphonic enable you to create custom tag library on top of LLM classification. Think through what you need according to your sales pipeline and CX process – no generics here.
Step 3: Automate the Feedback Loop
Insights stored in dashboards don’t change anything in behavior. Automate the feedback loop.
Objection spikes should be routed to the sales enablement team, while sentiment drops during onboarding, to customer success. Feature requests extracted from call recordings – to product.
The business value is clear. According to a study by McKinsey, businesses that leverage customer information to their advantage have 23 times greater probability to win over a customer and 6 times higher chance to retain a customer.
What Are the Ethical and Accuracy Standards in AI Call Analytics?
Ethics and compliance must be the basis for AI call analytics. Otherwise, it simply means there is no legality or reliability to the insights.
Transparency and Compliance
All jurisdictions have their own standards concerning call consent. For instance, US jurisdictions of two-party consent require both parties to give consent while GDPR applies throughout Europe.
The basic rule: consent all calls before recording starts. Your privacy protection redaction layer should work even before your transcript reaches an LLM. Document your consent framework and revise it as you enter each new market. If you want a deeper understanding of recording regulations, encryption, and privacy safeguards for AI conversations, read our guide on AI phone call security and compliance.
High-Quality Transcription is a Must Have
Analyze the wrong transcriptions and you are doomed to fail. GIGO works perfectly for NLP pipeline.
Use acoustic models trained specifically for your domain if you deal with specific language like healthcare, automotive, legal, financial services. Generic models won’t recognize specific terminology.
To learn more about the ways in which Botphonic integrates call intelligence with call compliance, check out the features of Botphonic’s AI-powered phone calls. To discover how to deploy conversational AI solutions throughout the whole customer journey, take a closer look at the way Botphonic implements AI-enabled customer conversations.
Conclusion: Future-Proofing Your Customer Strategy
Your call recordings aren’t a compliance database. They are a constantly renewed dataset of customers’ language, objections, sentiments, and product insights.
Those organizations that consider them a form of archiving are essentially working in the dark on their key research resource. Those organizations that use them in combination with artificial intelligence via acoustic analysis, diarization, PII redaction, and LLM-based tagging get a compounding strategic edge that is unmatchable by any survey project.
Your step to take this week: Collect your 30 days’ worth of call recordings. Transcribe them. Search your top three sales objections based on keywords. Count how many times each appears and when during the call it occurs. This one simple analysis will reveal to you what your call data was hiding.